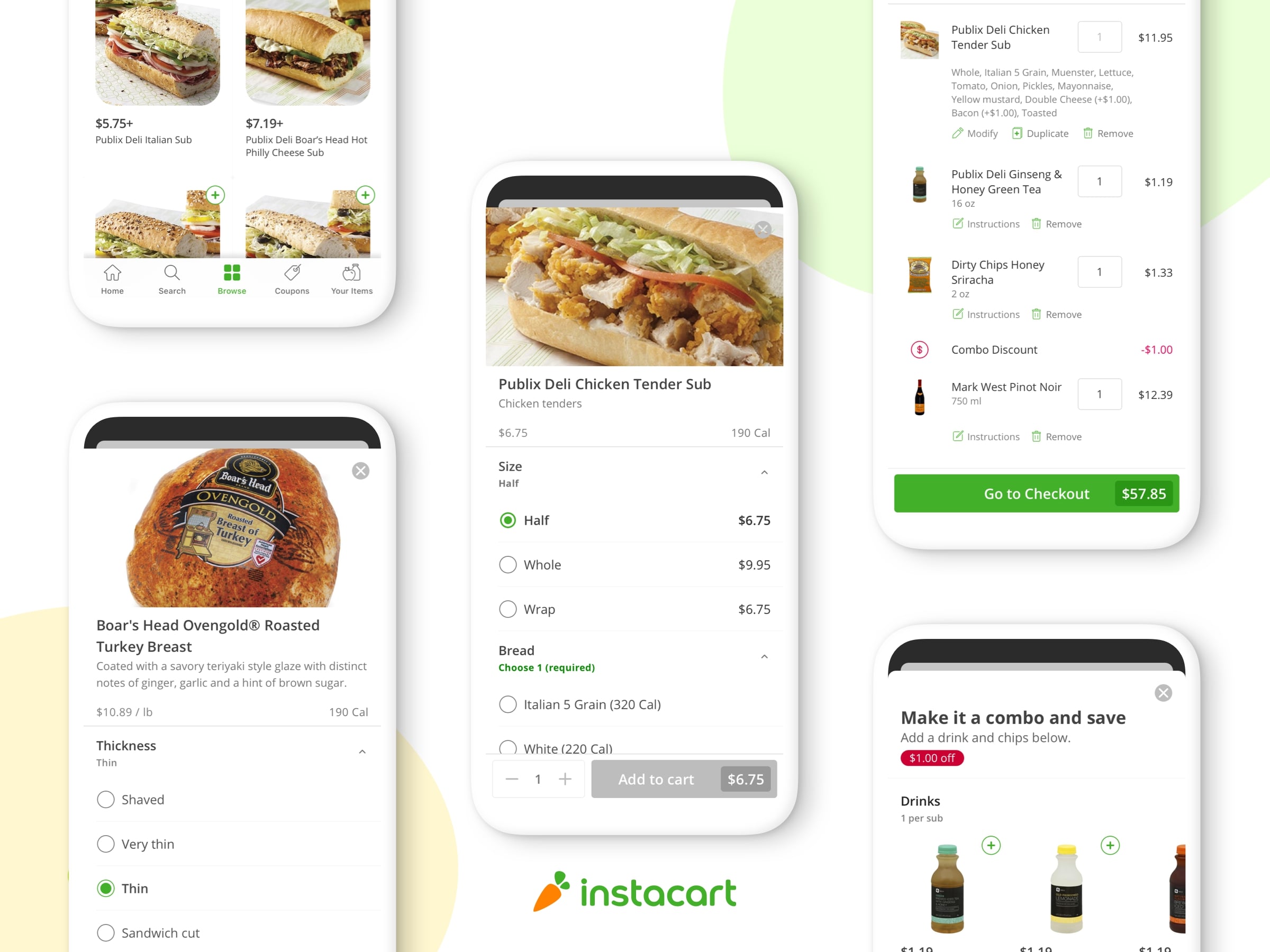
これは「注文の裏話」シリーズのパート3です。今回はアプリで食料品を洗い出し、店頭での購入を可能にし、買い物プロセス中のコミュニケーションを促進し、顧客が注文した食材を 1時間以内に届ける物流の裏話を紹介します。 またパート1:食料品カタログデータを収集して正規化する方法とパート2:店頭での購入の購入プロセスの技術の裏話も是非チェックしでください。
前回の記事では、お気に入りのレモンハーブサーモンの材料を簡単に見つけて購入できる技術について紹介しました。 今回は、メイヤーレモン、フレッシュディル、サーモンフィレの食材の在庫があるかどうかを判断するのに役立つ予測モデルについて話します。 また、顧客が好みのアイテムの交換を簡単に選択して伝達できるようにする機械学習モデルも語ります。
トレーニングデータ
カタログデータは、私たちのマーケットプレイスの技術的基盤です。
カタログには約500万のユニークな商品があり、合計で約950,000,000件の商品リストがあります。 これらの各リストには、名前、製品ID、および部門、通路番号、食事/料理のタグ、栄養情報などのいくつかのサブ属性があります。 また、店頭である商品の購入に関しての履歴データにも依存しています。 このデータには、アイテムの入手可能性(在庫可能性)の履歴、アイテムが交換品として選択された回数などが含まれます。

このデータを組み合わせることで、多くの機械学習モデルが強化されます。 特に2つのモデルは、お客様とショッパーがスムーズに買い物できるように確保するために連携して機能します。それはアイテム在庫モデル(Item Availability Model )と交換推奨モデル(Replacement Recommendation Model)です。
アイテムの在庫可能性を特定
私たちのモデルは30分ごとに5億件を超えるリスティングの在庫可能性を予測しています。
在庫状況モデルは、小売店の在庫状況の履歴データ、店舗の場所、商品の購入履歴、ショッパーが入力する情報に基づいて、カタログ内の特定の商品が25,000近くの実店舗のいずれかに在庫があるかどうかを予測します。
これは本当に難しい。 小売パートナーからアイテムの在庫可能性については1日に1回程度でデータを得ていますが、ご存知のように、在庫状況は1日を通して変動は激し場合があります。 1日1回データをもらうのでは、適切に1時間ごとの予測が得られません。特に、Meyer Lemonのようにちょっと珍しいフルーツ品種の場合は、より難しくなります。 一部の店舗では、生産者から季節ごとに新しい貨物が届く場合があります。 また、果物が季節になると、一部の店舗では午前中のみレモンを補充する場合もあれば、1日に複数回在庫を補充する店舗もあります。
1日の変動性を理解するために、時間中心のデータ機能(特に、店内でショッパーが商品を選んだ時刻と曜日)を調べるモデルを構築し、各リストに在庫可能性の点数をつけます。

アイテムの在庫状況モデルの詳細については、私たちの機械学習エンジニア、 Abhay Pawar Sr.さんが書いた記事をご覧ください。
適切な代替品を洗い出す
通常、自分で買い物をする顧客は、探している商品の7%交換します。
悲しいことに、お気に入りの小売業者からメイヤーレモンの在庫可能性の点数が低かったことが分かりました。 これが発生すると、交換推奨(Replacement Recommendation)モデルを引き継いで、顧客向けのアプリでフローを起動し、閲覧時、顧客に事前に代替品を選択するよう求めます。

メイヤーレモンがない場合、代わりに有機レモン、有機レモン/バッグ、非有機レモン、またはMeyerレモンジュースに置き換えますか?
交換を特に予測するのが難しいのは、顧客が商品を購入する際のいろいろな使い方にあります。 たとえば、サーモンの上にレモン汁を絞って風味を付けたい場合は、代わりにレモン汁を選ぶことができますが、レモンスライスでサーモンを飾りたい場合は、オーガニックレモンが必要な場合があります。
現在のモデルは、商品名やアイテムの交換履歴などのカテゴリデータの組み合わせに基づいて、関連するアイテムリストとスタックランクの潜在的な交換品を分けます。
いくつかの理由でスコアリングする場合、置換履歴などの履歴データにカテゴリデータよりもはるかに重要視します。履歴データは、カテゴリデータ(通路、部門、名前)のレンズを通して見ると非定型的な交換品のように見えるが、人間にとっては完全に普通なアイテムを見つけるのに役立ちます。メイヤーレモンの場合、顧客はだいたい、メイヤーレモンジュースを代替品として選択しますが、この選択肢は通常、農産物セクションにはありません。 過去の購入履歴や顧客の嗜好に点数を付けることで、Ms. Meyerのレモンソープなど名前から見ると関連性が強い商品にもかかわらず、ジュースがはるかに広く好まれていることがわかります。
顧客が事前に代替品を選択せずにショッパーに任せることを選択した場合(約半分の顧客はこのオプションを選びます。)交換モデルは、ショッパーが選択できるアプリフローにいくつかの上位の過去の代替品を表示します。
在庫切れアイテムのような潜在的な問題を取り除くことは、フルフィルメントチェーンの成功にとって重要です。 これら2つの予測モデルは密接に連携して、1つのリスティングの在庫状況を設定し、注文のコンテキストをショッパーに迅速かつ簡単に伝える機会を作ります。そして、このシリーズの最後の記事では、ショッパーが店を通り、顧客に食料品を届けるまでの技術を紹介します。
データサイエンス、モバイル開発、機械学習をもっと詳しく知りたいですか? 私たちのエンジニアリングおよび商品チームが採用が行っています! 現在の募集をご覧ください。
原文タイトル:The story behind an Instacart order, part 3: predicting the shop
原文作者:Instacart

今だけ!登録で最大1,500円相当もらえるお仕事探しサービス「テクスカ」
「テクスカ」は、報酬をもらいながらお仕事探しができる新体験のスカウトサービスです。
【テクスカの4つの特徴】
1.面談するだけで、3,500円相当のAmazonギフトカードを獲得できます
2.優秀な貴方に仲間になってほしいと真に願うとっておきのスカウトが企業から届きます
3.貴方の経歴・スキルを見て正社員のオファーだけでなく副業オファーも届きます
4.転職意欲がなくとも自分のスキルが通用するか各社のCTOに評価してもらうチャンスがあります
忙しさのあまり、企業との新たな出会いを逃している…
スパムのように届くスカウトメールにうんざりしている…
自分の市場価値がわからない…
社外の人からの評価が気になる…
副業の仕事が見つからない…
そんなあなたにおすすめです!