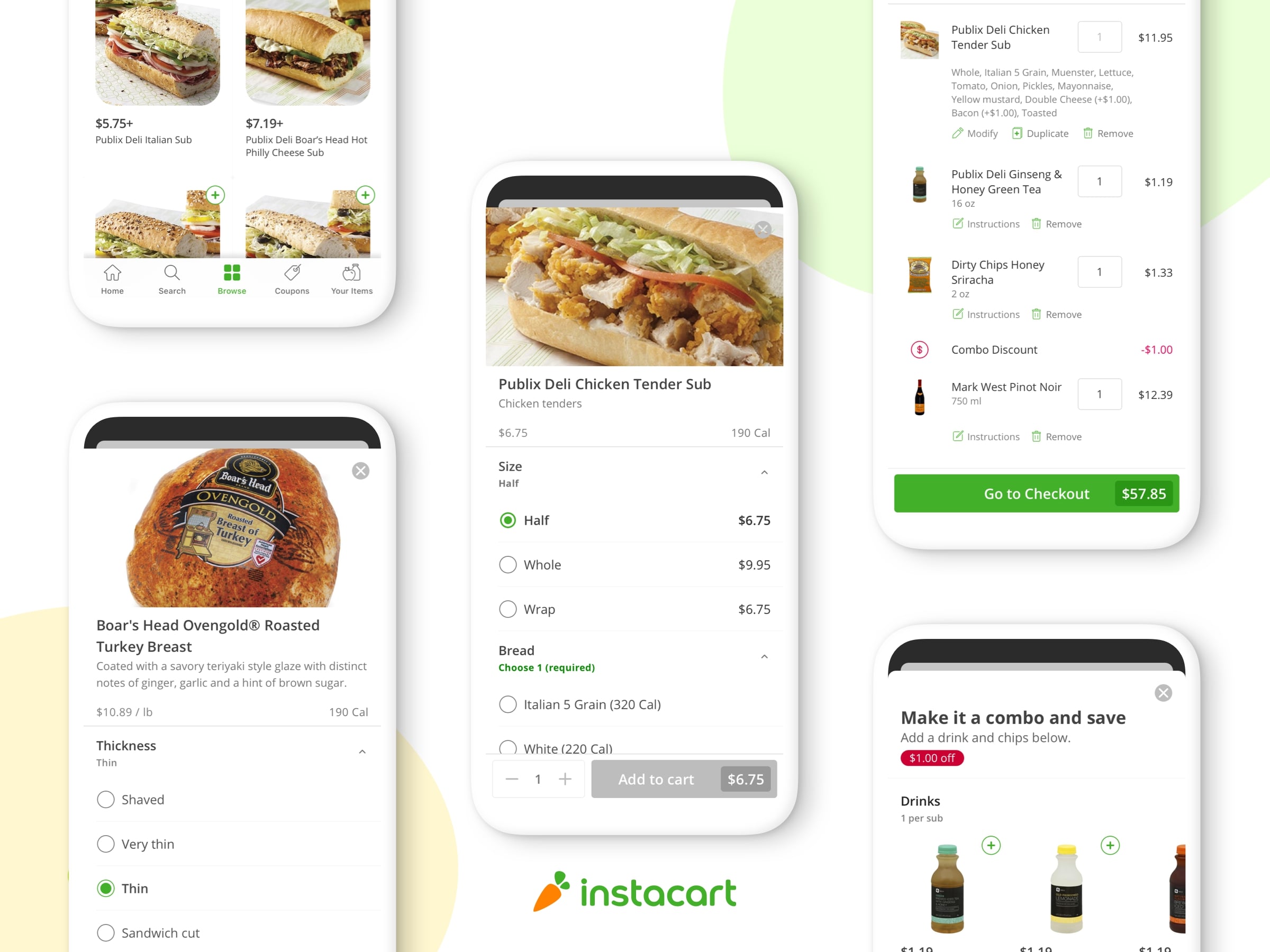
Instacartで遅れた配送(遅配)を減らす
スタートアップでは、プロダクトをゼロから作成する機会があります。 この記事では、Instacartの私の最初のプロジェクトを例として、貴重なデータサイエンスプロダクトを迅速に構築する方法を紹介します。
ここに問題があります。 Instacartのショッピングカートに商品を追加した後、顧客はチェックアウト時に配送ウィンドウ(配送の時間)を選択することができます(図1参照)。 その後、Instacartのshoppersは、注文通りに届けようとします。 混雑する時には、当社のシステムでは、処理できる注文数よりも多くの注文を受け入れ、遅れて注文するものもありました。
私たちは、遅れの問題に対処するためにデータサイエンスを活用することに決めました。 この考え方は、データサイエンスモデルを使用して各ウィンドウの配信キャパシティー(delivery capacity)を見積もり、注文数がそのキャパシティーに達するとウィンドウが閉じられるようにすることでした。
ここに10日間でv1製品を構築した方法があります。

図1.顧客は、利用可能な配達ウィンドウを選択することができます。
Day1. 企画する
私たちは、適切なものに取り組み、迅速なソリューションを開発できるように、計画を立てました。
・最初に、プロジェクトの進行状況を測定するための指標(メトリック)を定義しました。
・2番目に、我々は高いインパクト(low-hanging fruit)で達成可能な領域を特定しました。
・最後に、簡単に実装できる簡単なソリューションを思いつきました。
メトリック 1日あたりの遅配のパーセンテージを用いて、遅延を測定しました。私たちは配信ウィンドウをあまりにも早く終了させたくないので、時間通りに配信される可能性のある注文をキャプチャできませんでした。したがって、1日あたりの配信数がカウンタメトリックとして使用されました。 (現在、shoppersの利用度をカウンターメトリックとして使用しています)。
Low-hanging fruit. データは、多くの遅配が前日に注文したことを示しています。 そのため、翌日の配信ウィンドウ(図1:明日のウィンドウ)に重点を置くことにしました。
解決 時間ウィンドウT(TとT + 1との間)内に注文を送るために、shopperはTの前の注文を処理し始めることができます。図2は、shopperがウィンドウT-2の注文に取り組み始め、 大部分の注文は2時間未満で済むので、配送ウィンドウTのキャパシティーは、主に時間ウィンドウT、T-1、およびT-2におけるshoppersの数に依存します。

図2どれくらい注文に費やされたshopperの時間の図。
線形関係を仮定すると、配信ウィンドウTの容量は、以下のように書くことができます。
capacity(T) = a+b0*#shoppers(T)+b1*#shoppers(T-1)+b2*#shoppers(T-2)
キャパシティーにも影響を与える他の要因(天気など)があるかもしれませんが、我々は簡単に始めることに決めました。
Day 2–3. モデルの最初の反復
我々はフィーチャーエンジニアリング、トレーニングの作成とデータのテスト、および異なるモデルの比較という典型的なモデリングプロセスに従いました。 しかし、いったんモデルが合理的に正確であると感じると、モデルに時間を費やすことはありませんでした。 まず、モデルはシステムの一部にすぎませんでした。 それに、モデル精度の改善は必ずしもメトリクスの改善と同じではありませんでした。
機能とデータ 過去の各配信ウィンドウでは、ウィンドウ内で配信されたオーダーと、オーダーに費やされたshopperの時間というデータがありました。 図3は、時間ウィンドウT(TとT + 1との間)に配信された3つの注文を示し、ウィンドウT-2に2人のshoppersがおり、ウィンドウT-1とTの両方で3人のshoppersが働いていた。図4この例から作成されたデータです。

図3 T時間内に配信された3つの注文(TとT + 1の間)では、2人のshoppersがT-2ウィンドウで働き、3人のshoppersがT-1ウィンドウとTウィンドウの両方で働いた。

図4.図3に示す例から作成された1行のデータ。
線形モデル。 レスポンス変数として#orders(T)を使用し、他の変数をプレディクタとして使用し、トレーニングデータセットに線形モデルを作成し、検証データセットでテストしました。 モデルの形式は以下の通りです
#orders(T) = a+b0*#shoppers(T)+b1*#shoppers(T-1)+b2*#shoppers(T-2)
検証データの予測値対実際の値を図5(左)に描きます。 各予測値と45度線での実際の値の平均も描かれています。
非線形モデル。 比較のためにランダムなフォレストモデルを構築しました。 予測値対実際の値を図5(右)に描きます。 ランダムフォレストモデルは線形モデルよりも大幅に優れていなかったため、解釈と実装するのが簡単な線形モデルを使いこなすのが快適でした。
予測。 線形モデルを用いて、次の定式を用いて将来の配信ウィンドウTのキャパシティーを推定することができる
capacity(T) = a+b0*#shoppers(T)+b1*#shoppers(T-1)+b2*#shoppers(T-2)
この定式では、#shoppers(t)は、将来の時間ウィンドウt(t = T、T-1またはT-2)でスケジュールされたshoppersの数を表していることに注意してください。


図5.線形モデル(左)とランダムフォレストモデル(右)から予測vs実際のプロット。
Day 4–5. エンドツーエンド統合
データサイエンスとエンジニアリングのコンポーネント間のインタフェースとしてデータベースを使用しました。 このようにして、データサイエンスとエンジニアリング間の依存関係を減らすことができます(エンジニアリングコードにデータサイエンスモデルを埋め込むことと比較して)。そして、異なるコンポーネントの所有権を明確に定義することができます。 図6は、システムの動作を示しています。
データサイエンスのコンポーネント 事前定義された頻度でcron(時間ベースのスケジューラ)によってトリガされる2つのデータサイエンスジョブ、モデルトレーニングジョブおよび予測ジョブがありました。
モデルトレーニングの仕事は毎週行われ、最新のorder_shoppersデータ(注文とshoppersが注文に費やされた時間)を取り出し、モデルを適合させ、それらをデータベーステーブル(モデル)に保存しました。 予測ジョブは毎晩実行され、モデルとスケジュールされた時間(予定された買い物時間)のデータが取り出され、将来の配信ウィンドウのキャパシティーが推定されました。 見積もりは、capacity_estimatesテーブルに保存されました。
エンジニアリングコンポーネント キャパシティカウンティングジョブは、キャパシティ見積もりを消費し、顧客アプリの各ウィンドウの配信可用性を提供するために作成されました。 1分ごとに実行する予定で、キャパシティ見積もりと既存の受注を取得し、配信ウィンドウが利用可能であれば計算し、可用性情報をdelivery_availabilitiesテーブルに保存しました。 また、顧客が注文をしたときに、注文情報が注文テーブルに保存され、キャパシティカウントジョブがトリガーされます。

図6.データサイエンスとエンジニアリングコンポーネントの統合。
Day 6–8. モデルの2回目の反復
キャパシティ見積もりの健全性チェックを行い、2つのモデリングの問題が見つかって修正されました。
健全性チェック 将来の配信ウィンドウのキャパシティ見積もりを生成する予測ジョブを実行しました。 その後、ウィンドウが廃止された後、ウィンドウの推定キャパシティを既存のシステムが実際に受け入れたオーダーと比較しました。 いくつかのケースでは、既存のシステムが見積もり能力よりも少ない受注を取ったが、かなりの遅れを持っていることがわかった(図7参照)。 これは、これらのケースではキャパシティが過大評価されていることを示しています。 この洞察に基づき、2つの問題が見つかりました。

図7は、既存のシステムで受け入れられた注文と比較してキャパシティー見積もりを検証します。
問題1:平均予測 我々が構築したモデルは平均を予測した。 図5(左)から、平均線の下にデータポイントがあることが分かる。 平均予測は、それらのデータポイントのキャパシティーを過大評価することになります。 これを解決するために、予測間隔が構築され、より低いパーセンタイルレベルが使用された。 図8は、25パーセンタイルと75パーセンタイルのレベルを示しています。
問題2: データの不一致 予測で使用される#shoppersは、将来のウィンドウでスケジュールされたshoppersの数であり、shoppersは、(ウィンドウの前に)予定された時間をキャンセルすることができます。 しかし、モデルトレーニングに使用されたシャッフルには、中止された時間は含まれていませんでした。 したがって、予測とトレーニングに使用されたデータは一貫していませんでした。 それを修正するために、解約率(取り消し率)を推定し、定式に含めました
capacity(T) = a+b0*#shoppers(T)*{1-cancelation_rate(T)}+ …

図8.各予測値における実際値の25パーセンタイル値と75パーセンタイル値。
Day 9–10. 調整する
顧客に新しいシステムを導入する前に、(顧客に影響を与えずに)内部テストを開始し、それに応じて調整を行いました。
パーセンテイルレベル。 パーセンタイルレベルを調整して前のセクションで説明した健全性チェックに達するため。
キャッシング。 キャッシュは、データベースへの重複呼び出しを避けるために、頻繁に使用されるデータをサーバーに格納することで、ジョブを高速化しました。
ローンチ
図9は、プロダクトのローンチ時間によって遅延配信の割合を示しています。 新しいシステムは、遅れた配送を大幅に削減するという目標を達成しました(配送数を削減することなく)。 それはすばやく成功しました。 最初のローンチ以来、我々は同じ日の配信ウィンドウのキャパシティーを見積もることを含めて、繰り返し続けました。

図9.遅れた配達の日数によるパーセンテージ
要点
初めてスタートアップに入ったデータ科学者として、貴重なデータサイエンスプロダクトをすばやく構築する際に、以下の教訓(レッスン)を学びました。
- ・インパクトのある達成可能な作業の特定すること
- ・エンジニアリングとデータサイエンスのコンポーネント間の依存関係を軽減すること
- ・必ずしもモデルの精度ではなく、メトリクスの改善に集中すること
- ・シンプルで始まり、反復速度が速めにする
4年後、Instacartははるかに大きな会社になりました。ビジネス価値をすばやく提供するために行っているデータサイエンスプロジェクトに適用されています。
注:Andrew Kaneは最初のバージョンのエンジニアリングコンポーネントに貢献し、Tahir MobashirとSherin Kurianは後の反復に貢献しました。
🥕 Interested in joining us? Apply here.
タイトル:Building A Data Science Product in 10 Days
原文URL:https://tech.instacart.com/building-a-data-science-product-in-10-days-d2f4688567b0

今だけ!登録で最大1,500円相当もらえるお仕事探しサービス「テクスカ」
「テクスカ」は、報酬をもらいながらお仕事探しができる新体験のスカウトサービスです。
【テクスカの4つの特徴】
1.面談するだけで、3,500円相当のAmazonギフトカードを獲得できます
2.優秀な貴方に仲間になってほしいと真に願うとっておきのスカウトが企業から届きます
3.貴方の経歴・スキルを見て正社員のオファーだけでなく副業オファーも届きます
4.転職意欲がなくとも自分のスキルが通用するか各社のCTOに評価してもらうチャンスがあります
忙しさのあまり、企業との新たな出会いを逃している…
スパムのように届くスカウトメールにうんざりしている…
自分の市場価値がわからない…
社外の人からの評価が気になる…
副業の仕事が見つからない…
そんなあなたにおすすめです!