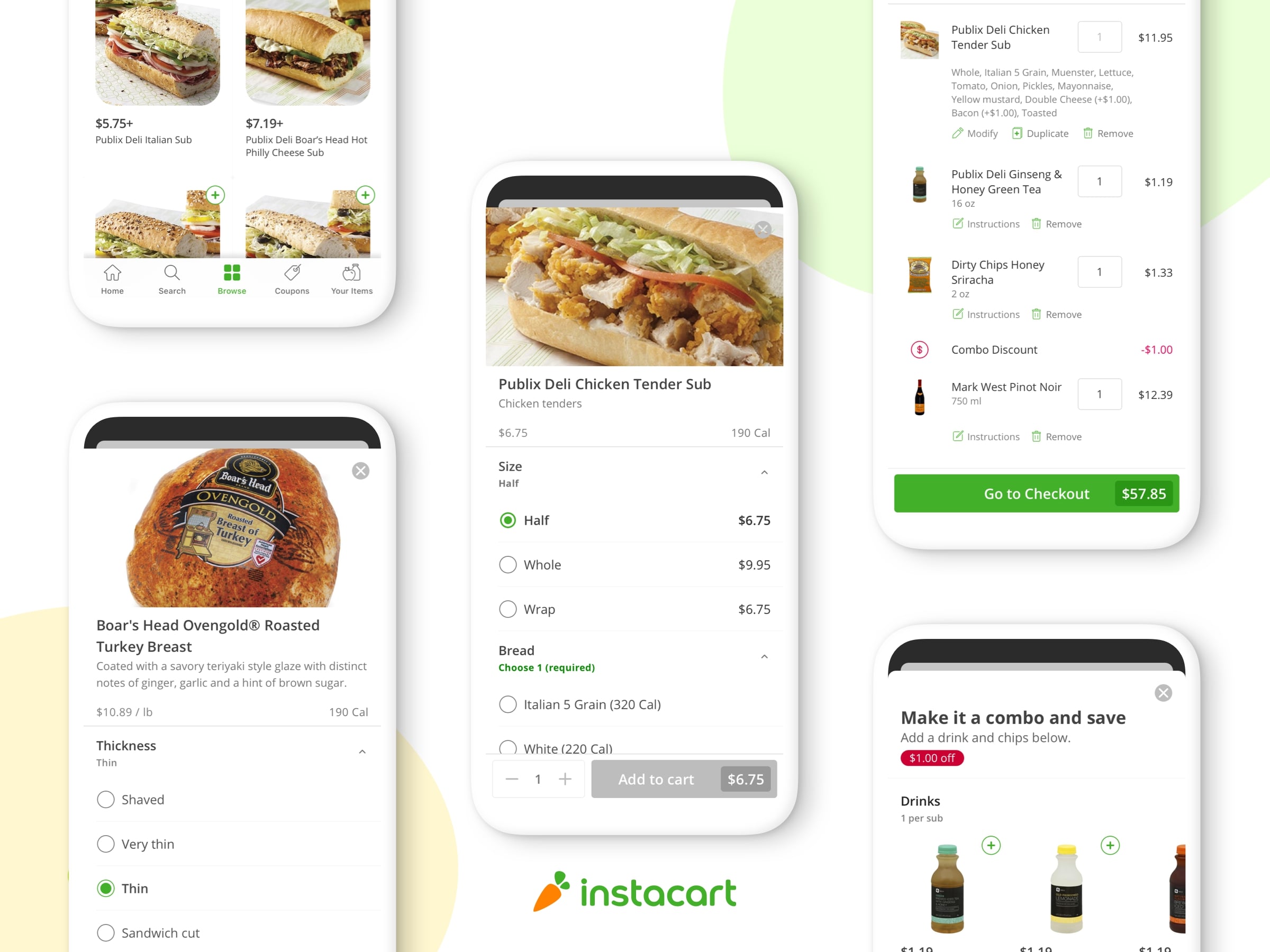
午後5時、あなたは帰宅中です。7時30分までに簡単な夕食を作りたいとします。そしてサーモンを作りたいのですが、冷蔵庫に3つのキー食材が欠けています:2.5ポンドの新鮮なサーモンフィレ、Meyerレモン一つ、新鮮なディル(ハーブの一種)1束です。iPhone上でInstacart Appを開き、カートにこれら3つのアイテムを追加し、6:00–7:00 pmに配達予定をセットして注文完了です。 1時間半後、オーブンを予熱している間に食材もドア前に届きました。

全てのプロセスは簡単に見えますが、その裏には複雑なシステムウェブがこの一連のプロセスをサポートしています。 これから、この「注文の旅」シリーズでは、我々のアプリで食料品を表示させ、店頭での閲覧を可能にし、ショッパーをガイドされ、そしてラストマイルロジスティクスを強化してその食材は1時間以内にあなたのドアまで届けるテクノロジーを紹介します。
今回の記事では、小売パートナーから食料品の属性と在庫データを取得し、場所と在庫をほぼリアルタイムで構成し、より大きな食料品の「カタログ」で使用可能な形式にデータを取得する方法について説明します。
食料品データの獲得
私たちのカタログは、世界最大のオンライン食料品カタログで、北米全域の約2万店の300以上の異なる小売業者からの5億以上の商品リストを持っています。
カタログ内の一つ一つの商品には、少なくとも、価格、名前、場所、UPC、およびSKUの属性のサブセットがあります。 複数の画像、栄養情報、季節情報、食事ラベル(グルテンフリー、kosher、veganなど)を含む、より詳細な属性のリストに対応できます。収集する属性が多いほど、より柔軟できめ細かいデータ分類が可能になります。 それもショッパーとお客様にとってもっと容易で検索することができます。
それで、どうやってこれらすべての情報を手に入れますか? そのためには、さまざまな精度のさまざまなデータソースを操作する必要があります。私たちのカタログは、小売業者、第三者のコンテンツアグリゲータ(情報を収集・整理して利用者に提供する事業者)、製造業者から直接提供されたデータ、さらにInstacartのショッパーやサイト管理者による「自家製」の食材まで、30件以上のデータソースで構成されています。
2つのレベルのアイテム属性を収集します。
- 店舗固有の属性:在庫状況、当地限定な特別商品、所在地別価格
- 商品固有の属性:名前、商品の説明、承認済み写真、栄養情報、サイズ/重さ

私たちは簡単なSFTPサーバーを使って小売業者からCSVファイルでデータを収集し、既存のデジタル化された商品データを持つ小売業者がリアルタイムで当社のシステムを更新できるようにするAPIも構築しました。 商品固有のデータは、多くの場合、店舗固有のデータを表します
カタログを更新する
Instacartは、世界中の1日のツイート数よりも毎晩多くのカタログデータポイントを更新します。
在庫、価格、その他の属性は刻々と変化します。カタログにそれらの変更を反映しないと、アプリが正確なリストさえも反映出来ません。そうなると顧客、ショッパー、小売業者、CPGパートナーに迷惑がかかります。創業時、未だほんの一部の小売業者と仕事していた頃から、私たちは業者が商品データについて定期的な最新情報を送ることができるツールを作りました。 特定の店舗で商品の価格が変わった場合、または商品の在庫が切れた場合、小売業者は在庫量や独自の技術インフラの詳細に応じて、いくつかの方法でInstacartに知らせることができます。
手動の1回限りの編集のために、私達は使いやすいWeb portalを構築し、そこで小売業者がいつでも好きな時に商品属性を追加できるフォーム入力機能を備えています。
そして業者たちも当社のSFTPサーバーにCSV ファイルを投げることができます。業者は自分が好きなタイミングや頻度で更新したファイルをアップすることができます – 多くの業者は一日一回それを更新しています。

上:バックエンドをちょっと覗きましょう。私たちは毎日の商品の更新を追跡しています。下:どのMeyerレモン画像が「最も理想的」な(属性)選択肢ですか? 左側の水平方向のレモン画像は右側の垂直方向のレモンを置き換えました。
洗練された在庫管理システムを社内で構築しているパートナーであることが一部の小売業者は、棚上の商品についての最新情報をリアルタイムで提供する「手持ちのバランス」データのリアルタイムストリームを提供してくれます。 私たちは、小売業者が在庫状況や商品属性の変化をリアルタイムで送信できるAPIを構築しました。
データ入力の優先順位付け
それは簡単なことです。 このデータがすべて揃ったら、どのようにしてそれをきれいにしますか? カタログに掲載されている商品の一覧について、最も正確で最も一貫性のある商品属性をどのように判断しますか。 最も正確な属性を見つけるには、情報源を互いに突き合わせ、入力に優先順位を付ける必要があります。
商品の在庫(入手可能性)は店舗固有の属性であり、これが私たちの顧客およびショッパーの経験に大きな影響を及ぼします。 昨夜受け取ったCSVファイルデータから、Meyerレモンはアラバマ州Mobileの店舗で在庫があることが書いていますが、ショッパーのアプリは在庫切れを示している場合は、この二つのデータを比較し、どちらが正しいのか判断を下すのが我々の仕事です。
私たちは最初にこれに関する一連の発見的方法を構築し、データソースの信頼性をマクロレベルで比べ、Meyerレモンが実際に店にあるかどうかという質問に対する「最も正確な」答えを見つけたいのです。 これらのヒューリスティックを作成するために、少し古き良き人間の力を借りました。 たとえば、複数のショッパーがある場所で商品の在庫が切れている報告があり、こういった報告は*通常*第三者からのデータより信頼性が高いです。 直近の30分以内に小売業者が入力した更新は、昨夜アップロードしたCSVファイルよりも*通常*正確です。 しかし、もしショッパーと小売管理者が同時に違うインプットを送信した場合はどうなりますか? 私たちの規模では、この複雑な状況が常にあります。
しかし、人間の直感はこれまでしかあなたを導いてくれません。 カタログ内の商品リストがはるかに少ないときに、これらのヒューリスティックを作り上げました。 現在、私たちは毎日、より大量のデータを取り込むようにしています。そして、ショッパー、ブランド、そして小売業者から寄せられる情報はもっとたくさんあります。 現在、ノイズからより多くの信号を見つけて、スケールでより良い、よりきめ細かい優先順位付けモデルを構築するために、機械学習モデルを研究しています。 最終的にこれらのモデルを構築することで正確さが得られ、新鮮なアトランティックサーモンの切り身が店内にあるかどうか、または夕食の準備スケジュールに10〜15分追加して冷凍サーモンを解凍する必要があるかどうかがわかりやすくなります。
規模に合わせた構築:カタログ基盤
2018年だけでも、私たちは100以上の新しい小売パートナーを立ち上げ、それぞれが独自の店舗と商品固有の属性を持っています
私たちのデータベースインフラストラクチャは伝統的に(慣例で)「巧妙な」(artisanal)システムとして進化してきました。 一言で言えば、それは設計(architected)されていません。
日々パートナーが送るデータの山に追いつき大規模なデータ品質問題に対処することは、私たちのカタログチームにとっての主要な課題の1つです。 7年分のカタログデータと毎日何十億ものデータポイントが更新されている現在、「ビッグデータの問題」を処理するためのシステムを構築する必要があることを正確に認識しました。
面白い事実:パートナーはその日のどの時点でも在庫データを送ることができますが、現地時間の午後10時ごろにほとんどのデータが来るという事実に気づきました。当社のシステムの特定の部分(Postgresなど)は、これらの午後10時のピークロード時間を効率的に処理するように構成されていませんでした。 これを解決するために、カタログインフラストラクチャを、巧妙な(artisanal)システムから、安価なストレージを備えた分散システム上で実行されるSQLベースのインタフェースへと「リフトアンドシフト」し始めました。 私たちはそのストレージから計算を切り離しました、そしてこの新しいシステムでは、その仕事を統一するために私達の統一されたスケジューラーとしてAirflowとデータを保存し、そして照会するためにSnowflakeに頼ります。
インフラストラクチャを再構築することで、ロード時間を効率的に処理できるだけでなく、長期的に見てコストを節約し、データ優先順位付けモデルが進化するにつれて毎晩更新を増やすことができます。
サーモンフィレ、新鮮なディル、Meyerレモンの属性が最も正確で最新の「最良」のリスティングであると確信できるようになったら、そのデータを顧客が毎日使用するオンラインの店にまとめます。それでは次回の記事を楽しみしてください!次回の記事は顧客向けのアプリを活用するための技術について詳しく説明します。
データベースと図書館科学のことをもっと詳しく知りたいですか📚? 私たちのカタログチームは現在募集しています!是非チェックしてください。
原文タイトル:The Story Behind an Instacart Order, Part 1: Building a Digital Catalog
原文作者:Instacart

今だけ!登録で最大1,500円相当もらえるお仕事探しサービス「テクスカ」
「テクスカ」は、報酬をもらいながらお仕事探しができる新体験のスカウトサービスです。
【テクスカの4つの特徴】
1.面談するだけで、3,500円相当のAmazonギフトカードを獲得できます
2.優秀な貴方に仲間になってほしいと真に願うとっておきのスカウトが企業から届きます
3.貴方の経歴・スキルを見て正社員のオファーだけでなく副業オファーも届きます
4.転職意欲がなくとも自分のスキルが通用するか各社のCTOに評価してもらうチャンスがあります
忙しさのあまり、企業との新たな出会いを逃している…
スパムのように届くスカウトメールにうんざりしている…
自分の市場価値がわからない…
社外の人からの評価が気になる…
副業の仕事が見つからない…
そんなあなたにおすすめです!